
Big Data
一. 数据仓库
1) 数据库和数据仓库的区别
传统事务型数据库如 MySQL 用于做联机事务处理(OLTP),例如交易事件的发生等;而数据仓库主要用于联机分析处理(OLAP),例如出报表等。
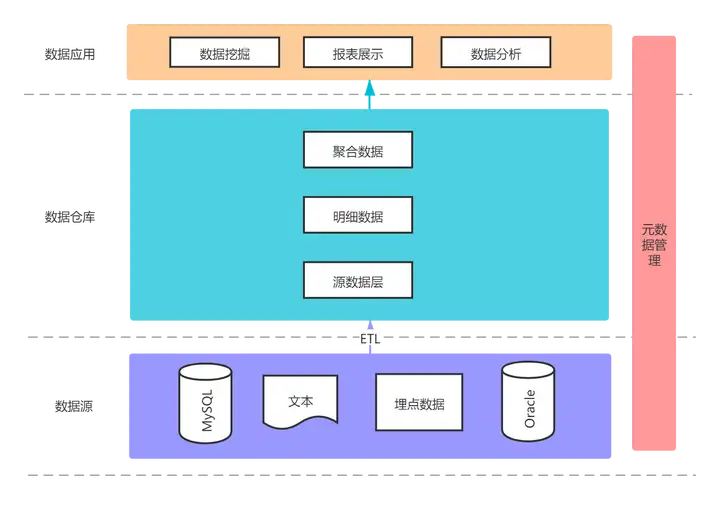
注:ETL - Extract、Transform、Load
数据清洗:

2) 数仓的特点
- 集成性
数仓中存储的数据来源于多个数据源,原始数据在不同数据源中的存储方式各不相同。要整合成为最终的数据集合,需要从数据源经过一系列抽取、清洗、转换的过程。
- 稳定性
数仓中保存的数据是历史记录,不允许被修改。用户只能通过分析工具进行查询和分析。
- 动态性
数仓的数据会随时间变化而定期更新,这里的定期更新不是指修改数据,一般是将业务系统发生变化的数据定期同步到数仓,和稳定性不冲突。不可更新是针对应用而言,即用户分析处理时不更新数据。
- 主题性
传统数据库对应的业务不同,数仓需要根据需求,将不同数据源的数据进行整合,即数据一般都围绕某一业务主题进行建模。例如“贷款”主题、“存款”主题等。
3) 数仓分层
数仓分层的意义在于
- 减少重复开发,在数据开发的过程中可以产生中间层,将公共逻辑下沉,减少重复计算;
- 清晰数据结构,每个分层分工明确,方便开发人员理解;
- 方便定位问题,通过分层了解数据血缘关系,在出问题的时候通过回溯定位问题;
- 简单化复杂问题,和分治法思想类似,分而治之,将复杂的问题简单化,还能解耦
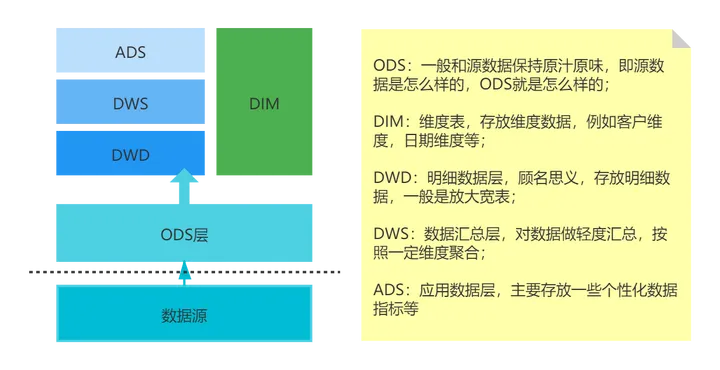
4) 数据仓库的pros/cons:
- 我们只能增加字段,很难去下线一个字段,真的要下线某一个字段,风险非常高
- 数据更新的底层是把整个表的数据重新生成一遍,再覆盖掉历史数据,成本非常高
- 增删改没有事务性保障,而在传统的数据库中有成熟的一致性解决方案
- 索引功能是有限的,一般很少建立索引,3.0版本已经没有索引了
- 无法满足算法人员对数据的所有诉求,比如在机器学习场景中,需要一些文本、语音、视频等非结构化数据
- 流批一体开发周期长,当下最流行的流批一体开发模式是基于lambda架构的,这种模式需要同时进行离线和实时的单独开发
二. 数据湖
1) 数据湖是什么?
数据湖是一个集中式存储库,允许存储所有结构化和非结构化数据
2) 聊聊数据湖和数仓之间的区别
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 结构化数据,抽取自事务系统和业务应用系统 | 所有类型的数据,结构化,半结构化和非结构化 |
| schema | 通常在数仓实施之前设计但也可以在分析时编写 | 在分析时编写 |
| 性价比 | 起步成本高,使用本地存储以获得最快查询结果 | 起步成本低,计算存储分离 |
| 数据质量 | 可作为重要事实依据的数据 | 包含原始数据在内的任何数据 |
| 用户 | 业务分析师为主 | DS, Data developer |
| 分析 | 批处理报告,BI,可视化分析 | ML, EDA, batch processing, feature analysis |
3)数据湖主要有以下特性
- 能够存储海量的原始数据
- 能够支持任意数据格式的数据
- 有较好的分析和处理能力
4) 湖仓一体是什么?
湖仓一体是一种新的数据管理模式,将数据仓库和数据湖的价值进行叠加,让湖中的数据可以流到数据仓库中;而数据仓库中的数据也可以保存于数据湖中,供数据挖掘时可以使用。通过将数据仓库和数据湖两者之间的差异进行融合,并将数据仓库构建在数据湖上,从而有效简化了企业数据的基础架构,提升数据存储弹性和质量的同时还能降低成本,减小数据冗余。
三. MySQL
数据库设计三大范式:
1) 第一范式 (确保每列保持原子性)
如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
2) 第二范式(确保表中的每列都和主键相关)
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
3) 第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
SQL优化
1) 避免使用SELECT *
2) 用UNION ALL代替UNION
3) 小表驱动大表 (IN - 优先执行子查询、EXIST - 优先执行exists左边的语句-主查询语句)
- in 适用于左边大表,右边小表。
- exists 适用于左边小表,右边大表。
4)利用索引优化